Source:https://arxiv.org/pdf/1706.03762.pdf
Expanding knowledge
1.RNN(Recurrent Neural Network)循环神经网络:为了能更好的处理前后相关的sequence信息提出了RNN。假设该网络在输入为xt,隐藏层为st,输出为ot,前提下,st的值不仅取决于xt,还取决于st-1
提出RNN的原因是CNN和人工翻译都假设输入输出的相互独立的,但RNN可以解决输入输出不独立的情况,将神经网络加入记忆。再使用激活函数进行非线性映射过滤无用的信息,只记住重要的信息,使用softmax来进行预测下一个词出现的概率,预测时要带权重矩阵。
[^与CNN相同,RNN每个cell都共享(U,V,W),极大降低计算量]:
双向RNN是在RNN的基础上预测当前状态需要考虑前后的信息。
2.CNN(Conventional Neural Network)卷积神经网络
3.LSTM长短时记忆(Long Short Time Memory):
1.处理和预测时间序列中间隔和延迟相对较长的重要事件(在词汇预测中如果关联词相差较远,RNN就会出现“梯度消失”的问题
2.三种门:遗忘门(丢弃的信息)、输入门(新加入的信息)、输出门(输出的信息)

attention机制
与RNN,CNN不同,完全采用的是attention机制,具有更强的的并行性、节约了训练的时间
Abstract
seq翻译模型主要基于复杂的recurrent or convolution 神经网络,它包括一个解码器一个编码器,表现最好的模型也通过注意力机制连接了解码编码器。
S:Transformer仅仅基于注意力机制,与CNN,RNN均无关,发现Transformer具有更好的并行性,使用了更少的时间去训练。
C:28.4BLEU on WMT2014 English-to-German translation task,我们发现Transformer也可很好的推广到其他任务,like English constituency parsing both with large and limited training data.
Introduction
Recurrent model通常沿着输入输出的标记位置进行计算,将position与当前时间对齐生成隐藏状态ht,作为ht-1的函数以及position t的输入,对于长序列的处理至关重要,因为内存有限制,最近通过factorization tricks and conditional computation提高了计算效率,后者提高了模型的表现,但顺序计算的限制依旧存在。
Background
基础是Extended Neural GPU,ByteNet,ConvS2S,它们中两个词汇之间的依赖关系与两者之间的距离反相关,这样如果两个词汇的距离太远它们的依赖性就很难体现。Transformer模型针对这种缺陷提出了Multi-Head Attention,Transformer模型没有使用RNN,CNN,它全部使用了attention机制对整个机制进行监控。
Model Architecture

Encoder: 6 identical layers,Each layer has 2 sub-layers.One is Multi-Head Attenion,The other is a feed-forward network.Between the two sub-layers,there is a residual connection followed by layer normalization(dmodel=512).output is **
$$
LayerNorm(x+Sublater(x))
$$
**Decoder:compared with encoder,the decoder has 3 sub-layers,the 3rd layer perform multi-head attention over the output of the encoder stack.The attention ensures the prediction for position i depend only on the pre-position.
basic knowledge
Embedding:引用one-hot方法词向量会很高维而且稀疏,使用Emedding更能找出词向量的相似性,这样就可以进行降维操作。计算嵌入矩阵前首先确定潜在因子,将个别单词用潜在因子组成的向量进行表示,其他单词可以用矩阵中向量的索引表示,探索具有相似性的词语,利用降维技术对词语进行相似性可视化。
positional encoding
对位置不敏感的模型(模型的输出不随着文本数据顺序的改变而改变)分为两类,Sinusoidal Positional Encoding(相对)和Learned Positional Encoding.(绝对)
[^绝对是对不同位置随机初始化一个position embedding,相对位置向量:用正余弦函数分别表示绝对位置,然后用乘积表示绝对位置,complex embedding使用复数域上连续函数来编码词在不同位置的表示]:
AR模型(Auto-regressive)and MA(Moving-average)模型
- AR自回归模型

[^本身前面的数据影响后面的数据(自相关),ut表示白噪声,在时间序列中数值随机波动,θ自回归系数]:
MA移动平均模型

[^对时间序列的白噪声序列进行加权和,得到移动平均方程]:
Attention
the output is computed as a weighted sum of th values,where the weight assigned to each value is computed by a function of query with the corrsponding key.

1 Transformer 模型直观认识
首先来说一下transformer和LSTM的最大区别, 就是LSTM的训练是迭代的, 是一个接一个字的来, 当前这个字过完LSTM单元, 才可以进下一个字, 而transformer的训练是并行的, 就是所有字是全部同时训练的, 这样就大大加快了计算效率, transformer使用了位置嵌入 (𝑝𝑜𝑠𝑖𝑡𝑖𝑜𝑛𝑎𝑙 𝑒𝑛𝑐𝑜𝑑𝑖𝑛𝑔) 来理解语言的顺序, 使用自注意力机制和全连接层来进行计算, 这些后面都会详细讲解.
transformer模型主要分为两大部分, 分别是编码器和解码器, 编码器负责把自然语言序列映射成为隐藏层(下图中第2步用九宫格比喻的部分), 含有自然语言序列的数学表达. 然后解码器把隐藏层再映射为自然语言序列, 从而使我们可以解决各种问题, 如情感分类, 命名实体识别, 语义关系抽取, 摘要生成, 机器翻译等等, 下面我们以机器翻译为例简单说一下下图的每一步都做了什么:
- 输入自然语言序列到编码器: Why do we work?(为什么要工作);
- 编码器输出到隐藏层, 再输入到解码器;
- 输入 <𝑠𝑡𝑎𝑟𝑡> (起始)符号到解码器;
- 得到第一个字”为”;
- 将得到的第一个字”为”落下来再输入到解码器;
- 得到第二个字”什”;
- 将得到的第二字再落下来, 直到解码器输出 <𝑒𝑛𝑑> (终止符), 即序列生成完成
2 Transformer Block结构图
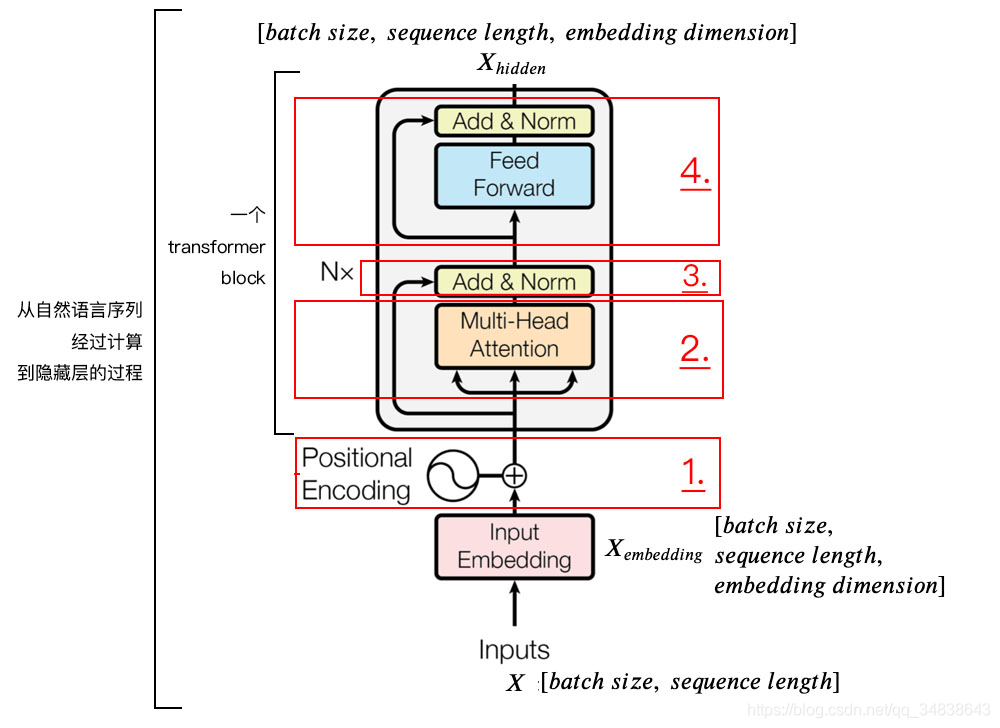
编码器的输入X是一个自然语言序列,它的维度是[batch size,sequence length],batch size是一次训练句子的个数,sequence length是句子的长度。它通过查阅字向量表或者其他方式得到每个字embedding dimension维的嵌入向量。
上面是一个transformer block,实际网络中可以堆叠多个block。
我们通过编码器输出的X h i d d e n X_{hidden}X*hidde*n就是隐藏层,下面详细介绍每个模块。
2.1 𝑝𝑜𝑠𝑖𝑡𝑖𝑜𝑛𝑎𝑙 𝑒𝑛𝑐𝑜𝑑𝑖𝑛𝑔
加position encoding是因为trandformer与LSTM不同,不是循环生成的
由于transformer模型没有循环神经网络的迭代操作, 所以我们必须提供每个字的位置信息给transformer, 才能识别出语言中的顺序关系.
注意, 我们一般以字为单位训练transformer模型, 数的线性变换来提供给模型位置信息:
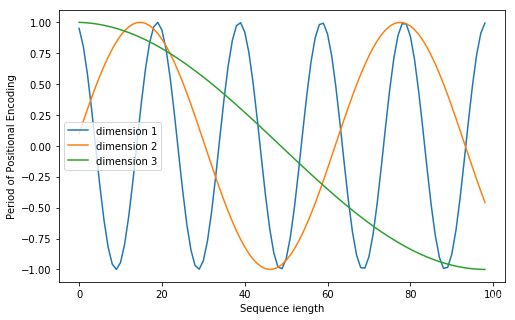
位置嵌入在e m b e d d i n g d i m e n s i o n embedding \ dimension*e\m*b*e*d*d*i*n*g\ *d*i*m*e*n*s*i*o*n*维度上随着维度序号增大, 周期变化会越来越慢**, .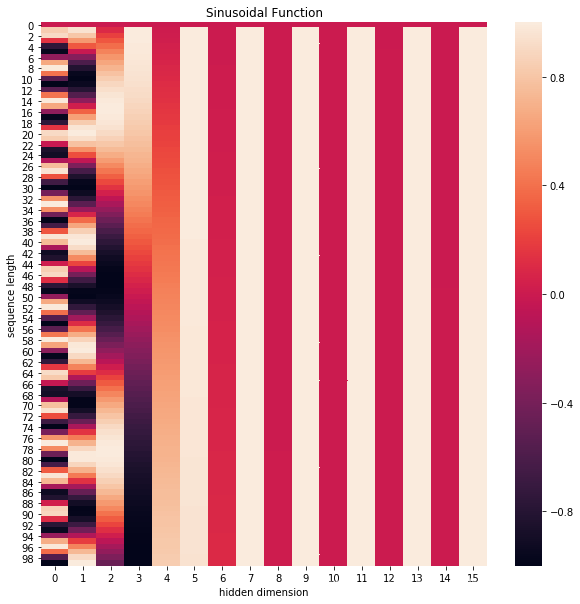
2.2 𝑠𝑒𝑙𝑓 𝑎𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑚𝑒𝑐ℎ𝑎𝑛𝑖𝑠𝑚


Attention Mask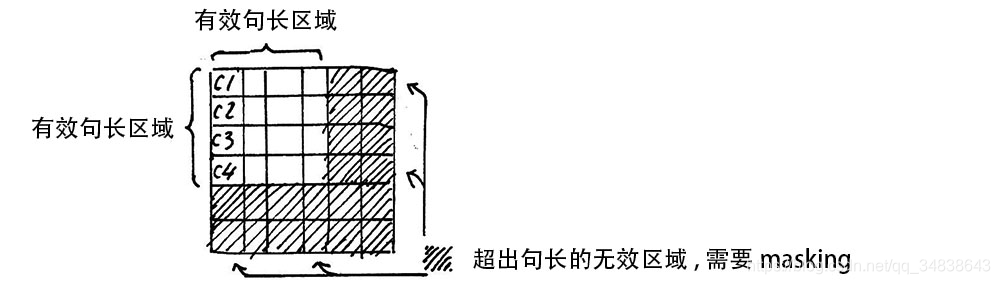


自己总结的图

BERT
BERT(Bidirectional Encoder Representations from Transformers)
Reference
2.
3.https://blog.csdn.net/qq_35799003/article/details/84780289
4.https://blog.csdn.net/qq_39422642/article/details/78676567
5.https://www.bilibili.com/video/BV1Mt411J734
https://github.com/aespresso/a_journey_into_math_of_ml


