p1.Train/dev/test sets
Train:训练集,用来训练各种模型
dev:验证集(development set)/Hold-out cross validation set,评估这些模型,通过迭代选出最优模型
test:测试集,需要对最终选定的神经模型进行最优估计(可选)
[^小数据集Train:dev:test=6:2:2 数据集较大(eg:100万data验证集和测试集可能只达到0.25%)]:
dev,test选择的数据来源需相同,才能有更好的效果
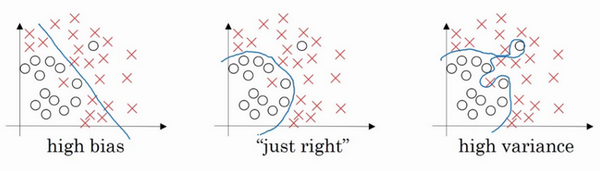
p2Bias/Variance偏差/方差
high bias:underfitting
high variance: overfitting

[^Train set error 小,dev set error大说明过拟合方差大 ;Train set error 大,dev set error小说明欠拟合偏差大]:
p3机器学习基础

P4Regulation

P5How does regularization prevent overfitting
if正则化参数设置的足够大,权重矩阵被设置为接近为零,基本上消除了隐藏的影响。这样就会从过拟合的状态接近高偏差的状态。
但会存在一个中间值,即“Just Right”状态。消除或减少许多隐藏单元的影响,神经网络会越来越接近逻辑回归,所有隐藏单元依然存在,但是神经网络变简单了。

如果正则化参数变得很大,参数W很小,z也会相对变小,此时忽略b的影响,z会相对变小,实际上,z的取值范围很小,这个激活函数,也就是曲线函数tanh会相对呈线性,整个神经网络会计算离线性函数近的值,这个线性函数非常简单,并不是一个极复杂的高度非线性函数,不会发生过拟合。
Dropout regularization(主要应用在cv)

[^keep_prob:保留每一个节点的概率。]:


如果某些层需要去除过拟合,那么keep_prob就需要设置的大一些。
p9归一化输入
一种加速神经网络训练速度的方法。

右图比左图的代价函数更容易找到min值,有图需要梯度下降迭代寻找。
p10Vanishing/exploding gradients
Vanishing gradients:接近于输出层的隐藏层由于其梯度相对正常,权值更新也相对正常。越靠近输入层,由于gradients消失,会导致靠近输入层权值更新缓慢或者停止。此时就导致训练时只等价于后面几层的浅层网络的学习。
p9.1 换用Relu、LeakyRelu、Elu等激活函数
ReLu:让激活函数的导数为1
LeakyReLu:包含了ReLu的几乎所有有点,同时解决了ReLu中0区间带来的影响
ELU:和LeakyReLu一样,都是为了解决0区间问题,相对于来,elu计算更耗时一些(为什么)
具体可以看关于各种激活函数的解析与讨论
p9.2 BatchNormalization
BN本质上是解决传播过程中的梯度问题,具体待补充完善,查看BN
p9.3 ResNet残差结构
具体待补充完善,查看ResNet
p9.4 LSTM结构
LSTM不太容易发生梯度消失,主要原因在于LSTM内部复杂的“门(gates)”
p9.5 预训练加finetunning
此方法来自Hinton在06年发表的论文上,其基本思想是每次训练一层隐藏层节点,将上一层隐藏层的输出作为输入,而本层的输出作为下一层的输入,这就是逐层预训练。
训练完成后,再对整个网络进行“微调(fine-tunning)”。
此方法相当于是找全局最优,然后整合起来寻找全局最优,但是现在基本都是直接拿imagenet的预训练模型直接进行finetunning。
4.5 梯度剪切、正则
这个方案主要是针对梯度爆炸提出的,其思想是设值一个剪切阈值,如果更新梯度时,梯度超过了这个阈值,那么就将其强制限制在这个范围之内。这样可以防止梯度爆炸。
另一种防止梯度爆炸的手段是采用权重正则化,正则化主要是通过对网络权重做正则来限制过拟合,但是根据正则项在损失函数中的形式:
可以看出,如果发生梯度爆炸,那么权值的范数就会变的非常大,反过来,通过限制正则化项的大小,也可以在一定程度上限制梯度爆炸的发生。
p32softmax回归
可以将输入数据分为多类。


[^直线边界代表决策边界]:



Class 5 sequence data-nlp(Natural Language Processing)
p2Notation
Reprsenting words
one-hot编码(UNK表示未标识)
p3Recurrent Neural Network

[^X<1>,….,X
RNN(Recurrent Neural Networks)
传统神经网络有两个缺点:
1.输入和输出序列的长度必须一致。
2.不同位置的特征无法
RNN只是用了之前的信息来预测当时的信息


